
文/洪介興
●問問你/什麼是抽樣誤差 什麼是信心水準
提前瞭解民眾當下對目前宣布參選的四組候選人的支持度有多高,各家媒體接連進行各項民意調查(簡稱民調)。以下這段文字取自《信傳媒》9月28日刊登的報導:
根據國家通訊傳播委員會111年度針對16歲以上民眾所做通訊市場調查,僅使用手機占51.7%、手機市話並用占40.5%,僅使用市話比例為7.8%,手機持有率高達9成2以上。《信傳媒》因此於9月18至22日進行「全手機」民調。
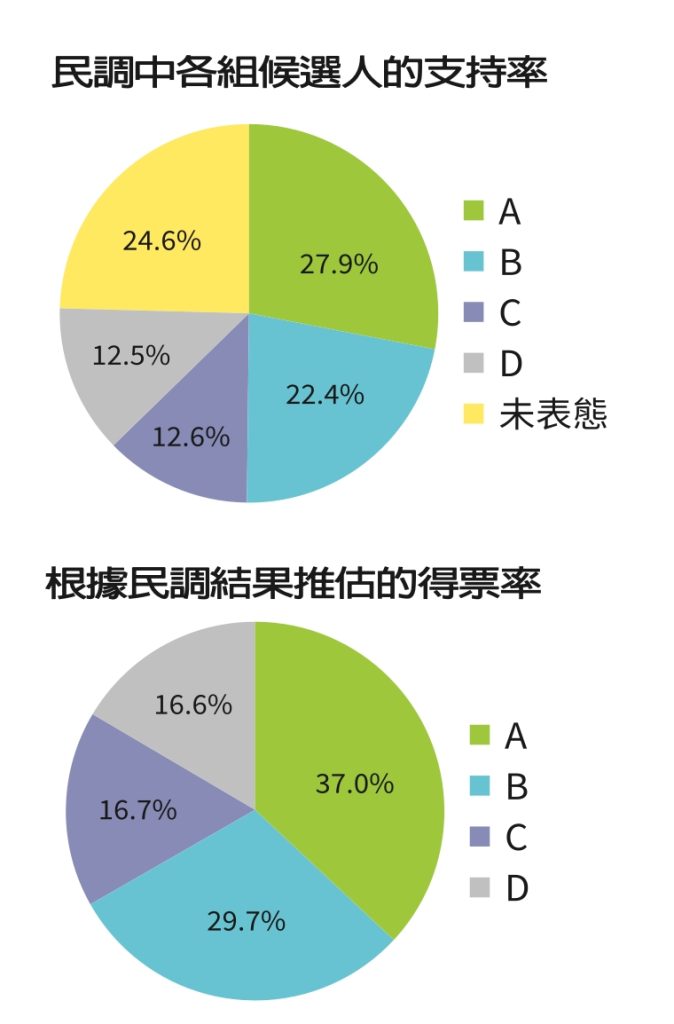
結果顯示,在四腳督戰局中,A政黨總統參選人獲27.9%、B政黨總統參選人22.4%、C政黨總統參選人12.6%、獨立參選人D 12.5%;另有24.6%還沒決定、不知道或不投票。
本次調查由《信傳媒》委託佳興智慧科技公司執行,針對設籍在全國22縣市、年滿20歲的民眾採「全手機」抽樣,調查期間在9月18日自中午12點到晚上9點,19~22日調查則自上午10點進行到晚上9點,總計完成訪問1213人,在95%的信心水準下,抽樣誤差是±2.81%。手機抽樣依電信公告前五碼為本,後五碼隨機。調查結果針對性別、年齡、戶籍地區、教育程度進行加權。
這篇報導你看得懂多少?看不懂多少呢?我們提出以下幾個問題,並接著針對這些問題進行探討:
①為什麼要強調「全手機」民調?
②怎麼解讀27.9%、22.4%、12.6%等數據?
③為什麼要訪問1213人這麼多?
④什麼叫做95%的信心水準?
⑤什麼叫做抽樣誤差±2.81%?
⑥什麼叫做加權?
⑦為什麼要針對這些項目進行加權?
●談抽樣/基本原則 每人機率相同 方法時間 會影響隨機性
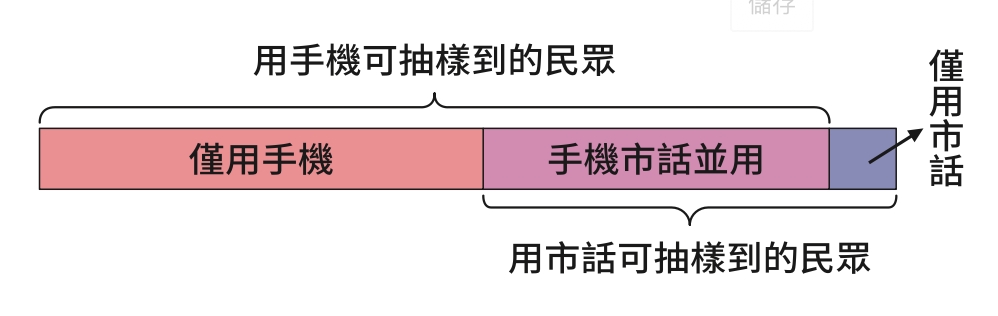
傳統的民調都是採用市內電話聯絡受訪者,但隨著時代的演變,手機已成為主要的通訊器材,許多人的住處甚至沒有裝設市內電話。愈是年輕族群,愈難以室內電話聯絡到。
理想上,隨機抽樣的調查是要讓每個人被抽到的機會相同。但報導中提到16歲以上的民眾中,手機市話並用占40.5%、僅使用手機占51.7%、僅使用市話為7.8%。若以市話進行調查,僅使用手機的民眾完全沒機會被抽到,這樣的民眾占有很高的比例;而若以手機進行調查,則是僅使用市話的民眾不會被抽到,這樣的民眾所占的比例很低;在此論點下,以手機進行抽樣確實可能是較佳的方式。
另外有些民調是採用市話、手機並行,這個方法感覺上可以涵蓋所有民眾,但又會產生另一個問題,就是手機市話並用的民眾會有較高的機會被抽到。因此這些抽樣方式都各有其不可避免的缺陷。
傳統的民調往往是在白天時段以市話進行民調。此方式還存在另一個問題,就是白天出門工作的民眾沒有機會被抽到。因此有些民調會聲明自己的調查時間,希望涵蓋各種不同時段,以維護抽樣的隨機性。
●談解讀/樣本中 包含未表態 支持度 不是得票率
著我們來談數據的解讀。以A政黨候選人的支持度27.9%為例,這個數據其實要和信心水準95%,以及抽樣誤差±2.81%一起看。完整說起來會是「根據此調查,A政黨候選人的支持度有95%的機會落在27.9%±2.81%的範圍內」。也就是說,實際的支持度大概會在25.1%~30.7%之間,但也有可能低於25.1%,或是高於30.7%,只是機會不大。
另外,雖然民調的目的就是預測得票率,但並不能把民調中的支持度直接看成得票率,這是因為實際開票的得票率不會把未投票及廢票計入分母。再以這份民調中A政黨候選人的27.9%支持度為例,因為這份民調有24.6%的未表態率,所以27.9%其實占了表態的75.4%當中的37%。若直接以等比例放大的方式,應該把A政黨候選人的得票率估計為37%上下3.7%(誤差亦等比例放大了)較為合理。
常見到有些政治評論員在解讀民調時,會直接把民調的支持度和該政黨過往的得票率進行比較,做出誤導民眾的評論,也不知是缺乏專業素養,還是有意為之。因此閱聽人在接受任何資訊時還是要審慎判斷,不能照單全收。
●告訴你/兼顧信心水準與誤差 有效樣本須達上千份
接下來的問題比較艱深,因為有效樣本數、信心水準、信賴區間這幾個概念是相互交織的,所以必須一併探討。
民調研究的對象是全國民眾,我們暫且假設全國目前(四捨五入到百分率小數第一位後)有27.0%的民眾支持A政黨候選人,如果民調可以把全國的民眾都問過一遍,就會得到27.0%這個準確的結果;但民調當然不可能調查全國民眾,只能抽一部分民眾作為樣本,並希望這些樣本可以呈現出相同的支持度。為了方便討論,我們就假設有效樣本數為1000(扣除因回答不完整而無法採計的樣本稱為有效樣本)。
如果這1000個有效樣本中,不多不少恰好有270人回答支持A政黨候選人,那麼這份民調的結果就會正好命中27.0%。但根據計算,在1000個有效樣本中要正好抽到270個支持者的可能性相當低,機率只有2.84%。也就是說,這民調要準到連百分率小數第一位都命中的機率只有2.84%,這個可能性實在太低了,因此我們必須容許一些誤差範圍。譬如我們若容許±1%的誤差,也就是26.0%~28.0%(抽到260~280個A政黨候選人的支持者)都算命中,那麼根據計算,這份民調的結果會有54.55%的機率落這個範圍內。
允許的誤差範圍愈大,就會有愈高的機率可以命中,這個命中的機率就叫做「信心水準」。我們當然希望信心水準愈高愈好,但信心水準愈高,誤差範圍就得要愈大。信心水準太低、誤差太大都不好,須在兩者之間取個平衡。實務上一般都是設定95%的信心水準,並根據此信心水準計算出對應的誤差範圍。
剛才我們提到信心水準與誤差範圍的矛盾,其實有一個方式可以既不降低信心水準,又可以縮小誤差範圍,那就是增加有效樣本數。一般而言,當有效樣本達到上千份時,95%信心水準的誤差範圍就可以縮小到3%左右,這已經是相當不錯的數字了,因此我們很容易發現幾乎每份民調的有效樣本數都是略多於1000。倘若我們希望95%信心水準的誤差範圍可以縮小到1%以內,大約要收集到上萬份有效樣本,那就要耗費大量的人力、物力了。
●談加權/支持度 影響因素很多 用加權 反映真實狀態
最後我們要探討的是何謂加權?為何民調要加權?
我們先回答何謂加權:假設現在有甲、乙兩位同學,甲同學上課非常認真,認真程度9分,課後複習不太認真,認真程度只有1分;而乙同學上課、課後複習都普通認真,認真程度都是5分。請問你覺得甲、乙兩位同學中,誰的學習比較認真?
有人可能會回答兩人一樣認真,因為甲、乙兩位同學的平均認真程度都是5分。但這個說法很容易會被另外一派攻擊,他們會主張上課時間比寫回家作業的時間多很多,所以甲同學一天中大多數的學習時間是很認真的,直接把9和1取平均實在不合理。譬如上課時間有6小時,而課後複習的時間是2小時,那麼甲同學就有6個小時的認真程度是9分,2個小時的認真程度是1分。因此應該要把9分算做有6份,把1分算做有2份,總共就有8份分數。這8份分數的平均是7分((9×6+1×2)÷8=7),這個分數稱為「加權分數」,把資料依照不同的重要性,看作有不同份數(如剛才例子中的6份、2份),這個做法就叫做「加權」,而6份和2份這兩個數字則叫做「權重」。
最後就是要說明為何民調要進行加權了。這是因為根據過往的統計資料顯示,性別、年齡、戶籍地區、教育程度這幾項因素,都和候選人支持度有很大的關聯性。假如某位候選人的政黨在中彰投地區有很高的支持度,但中彰投的樣本偏少,只占整體樣本的12%,遠低於中彰投實際占台灣人口總數的19.4%,但那麼這份民調就很可能低估這位候選人的整體支持度。因此可以用加權的方式,把中彰投的問卷賦予較高的權重,以此方式讓這份民調更能反映真實的支持度。
談了這麼多,我們也對民調有粗淺的認識了,但公職人員選舉最重要的還是要選賢與能。不能盲目投給民調高的候選人,而是要花時間去了解每位候選人的政見,以及每位候選人過往的作為,從中選出你理想的人選,這才是現代公民應具備的基本素養!
原文出自《好讀周報》740期


