文/曾慶良(阿亮老師)
最近看到一則新聞,運動賽事場地附近的居民抗議球場比賽時汽笛聲太大,讓「噪音」成為熱議話題。有許多人直覺認為,多支汽笛同時鳴響,聲音強度應該會倍增,分貝數值也跟著翻倍。但事實並非如此——這是因為我們對「分貝」的概念常有誤解。分貝是一種對數尺度的單位,多個聲源同時發聲時分貝並不能直接相加,兩個同樣大的聲音同時出現,總音量只會增加約3分貝左右,不會變成原來的兩倍。那麼,讓民眾感覺增加的「噪音」究竟是什麼產生的呢?
●分貝 代表聲音強度 強度加倍 分貝只加3
我們平常用分貝(記作dB)來表示聲音的大小(聲音強度或響度)。有趣的是,分貝並不像一般數值直接相加,而是一種對數單位。簡單說,每增加10分貝代表聲音強度增加了10倍,增加20分貝就代表強度增加100倍,以此類推。相反地,聲音強度減少10倍,分貝就降低10。由於人耳對聲音強弱的感受不是線性的,採用對數刻度可以更貼近人耳的聽覺感受,也讓超大聲和超小聲可以用較方便的數字來表示。
那兩支汽笛同時吹的情形該怎麼計算?其實只需記住一個重要規則:聲音強度加倍時,分貝只增加約3。讓我們用生活中的例子來體會這點:
假設一台收音機播音樂時量測是60分貝,開一台相同音量的收音機一起播放,總聲音強度會變成原來的兩倍。但兩台同時播放的分貝並不是60+60,而是約60+3=63分貝左右。只增加了3分貝!
同理,假如有4台一樣吵的收音機同時播放,總強度是單台的4倍,分貝數則只是再增加3分貝到約66分貝而已。所以,即使球迷們一起吹響10支汽笛,音量也不會真得大到原本的10倍那麼誇張。
不過要注意,分貝雖非線性累加,但多個噪音源疊加仍然會提高聲音強度,例如63分貝雖比60分貝只高一些,但人耳還是能感覺出變大聲了。
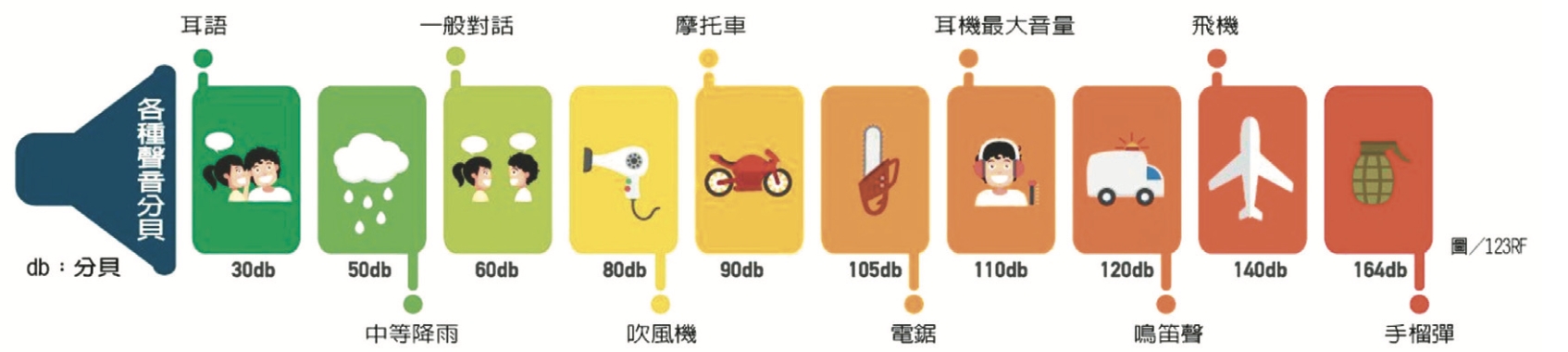
我們再參考一些日常經驗:例如,人在安靜室內低聲說話大約只有20~30分貝,普通交談音量大約是60分貝。繁忙馬路的車陣聲可以達到約85分貝(幾乎要提高嗓門才聽得到彼此講話),噴射機起飛時的引擎轟鳴甚至高達120分貝。由此可見,分貝值每增加一點點,代表的聲音強度可能差很多。這也是為什麼我們需要用對數刻度的分貝來描述聲音,才能同時涵蓋微弱的細語和震耳欲聾的巨響。
●頻率 決定聲調高低 赫茲 聲波振動次數
除了大小聲,聲音另一個重要的性質就是頻率。頻率決定聲音的音高,也就是我們聽到的聲調高低。簡單來說,頻率高的聲音聽起來尖銳(音調高),頻率低的聲音聽起來低沉(音調低)。頻率的單位是赫茲(Hz),代表聲波每秒振動的次數。人類能聽到的大約是20Hz到2萬Hz之間的聲音,而日常生活中的男聲、女聲或樂器聲,頻率各不相同。例如男生說話聲可能在100多Hz,女生聲音通常更高一些。
有趣的是,在音樂世界中,音高的變化並不是用加減多少Hz來表示,而是用乘除的比率來決定!西洋音樂的標準音階採用「十二平均律」,將一個八度的頻率跨度平均分成12個相等的比例。這意味著,相鄰的兩個音(如鋼琴上的白鍵和黑鍵)頻率之比都是一樣的。「十二平均律」中的這個等比倍率到底是多少呢?它其實就是2的1/12次方(即12次方根)。我們可以舉個具體例子來體會其中奧妙:
在鋼琴上,「中央Do」(即音名C4)通常約為261.6Hz左右。我們把中央Do的頻率乘上2的1/12次方,約等於乘上1.0595。
算算看:261.6Hz×1.0595≈277Hz。這就是比中央Do高半音的音(升C或稱Db)的頻率。繼續一階一階乘上1.0595,每往上一個半音,頻率都比前一音高出同樣的比例。經過12次這樣的等比遞增後,頻率將剛好乘上2(因為1.0595的12次方≈2)。也就是說,第12個音會回到下一個八度的Do,其頻率約為523Hz,剛好是原來中央Do頻率的兩倍!如此一來,我們就從數學上說明了為什麼一個高八度的音頻率正好是原音的兩倍。透過這巧妙的倍率設計,每個半音的差距一致,讓樂器可以在各個調之間自由轉換而不覺得走音。是不是很神奇呢?
順帶一提,這種頻率呈等比關係的設計,意味著音階愈往高處,每個半音之間的絕對頻率差其實愈大。例如中央Do到升C大約差了15Hz左右,而更高音域比如880Hz到下一音就差了將近50Hz。然而我們聽起來這兩種半音差距都是一樣的音程,這正是因為我們感受的是頻率比例而非差值。十二平均律便利樂器調音,背後蘊含著美妙的數學原理,掌握「高八度=頻率×2」,就能理解音高和頻率的基本關係了。
●每增加3分貝 安全暴露時間減半
長期處在喧鬧環境中不僅讓人心煩,還可能對聽力和身心健康造成損害。那麼多大聲音算「太吵」呢?專家常以85分貝作為一個重要門檻。一般來說,若在沒有任何聽力防護的情況下,處在85分貝左右的噪音環境中,長時間下來內耳的毛細胞可能逐漸受損,進而影響聽力。因此各國對勞工工作場合的噪音暴露標準多半訂在85分貝上下。生活中像機車引擎聲、繁忙馬路等都差不多接近這個級別。世界衛生組織甚至建議一般居住區的環境音量最好不要超過55分貝──雖然55分貝比起85分貝要低很多,但長期處在超過55分貝的環境下,可能已經讓人感覺不舒服、影響睡眠甚至提高壓力荷爾蒙分泌呢。
除了盡量降低噪音來源,還有一個評估噪音傷害風險的3分貝法則需要牢記:每增加3分貝,安全暴露時間減半。這意味著,如果在85分貝環境下可以安全待8小時,那提高到88分貝時安全時間就僅剩4小時;91分貝時縮減為2小時;再高到94分貝只剩1小時,以此類推。
舉個極端的例子來說,100分貝的環境(比如近距離使用電鑽或置身大型演唱會的音箱旁)大約15分鐘就可能達到聽力受損的風險門檻!這就是為什麼我們強調音量每增加一點,對聽力的傷害都不是線性增加,而是指數性上升。如果必須長時間處於嘈雜地方(例如工地、演唱會現場),務必戴上耳塞或防噪耳罩來降低分貝;或者定時讓耳朵休息一下,遠離噪音環境。總之,謹記「3分貝減半時間」這條原則,適時保護耳朵,我們才能長長久久地享受繽紛的聲音世界,而不讓噪音成為無形的健康殺手。
●AI精進相關技術 聲音應用改變生活
隨著人工智慧(AI)的進步,許多聲音相關的技術正在改變我們的生活。接下來,我們來介紹幾個AI時代的聲音應用,包括語音辨識、聲紋辨識和聲音複製,看看機器如何聽聲、辨聲,甚至開口學人說話。
★語音辨識 讓電腦聽懂人話
語音辨識(Automatic Speech Recognition, ASR)技術,就是讓電腦聽懂人說話的內容。以前我們和機器溝通只能打字,但現在透過語音辨識技術,我們對著手機講話就能叫它執行指令。
語音辨識的基本原理,是將聲音轉成數位訊號後,由AI模型分析其中的特徵,匹配語音和文字之間的關聯。早期的系統藉由統計模型配合字詞庫來「聽」,而近年來深度學習的引入讓語音辨識的準確率大幅提升。AI透過學習大量錄音與對應文本,可以逐漸「聽出」不同發音對應的文字。現在,我們的手機語音助理(如Siri、小愛同學)、導航系統、甚至智慧家電,都運用了語音辨識技術。未來語音辨識還可能應用在無接觸式控制、語音翻譯等更多場景中。可以說,讓機器聽懂人話,是AI時代人機互動的一大里程碑。
★聲紋辨識 辨別是誰在說話
聲紋辨識(Speaker Recognition)技術,簡單理解就是透過聲音來辨別說話者是誰。每個人的聲音其實就像指紋一樣獨一無二,因此聲紋辨識屬於生物識別技術的一種。原理上,系統會從一段聲音訊號中提取說話者的聲紋特徵(例如聲音的音高、共振峰、口音和說話節奏等),將這些特徵以數位方式保存。日後有聲音輸入時,再提取其特徵跟資料庫比對,就能確認說話者的身份。這有點像警方比對指紋找嫌疑人,但換成比對「聲紋」。
聲紋辨識的應用愈來愈廣泛。過去我們印象中,電視影集裡刑警分析錄音、從中找出嫌犯聲音,就是一種聲紋技術的運用。而如今在日常生活中,聲紋辨識也扮演了角色。例如,一些銀行的電話客服系統透過你的聲音就能識別你是否為帳戶本人,提高安全性。此外,智慧手機的語音助理可以被設定只對主人的聲音有反應(例如只能由主人的「嘿Siri」來解鎖),這也是聲音辨識身份的應用之一。甚至現在有研究利用聲紋技術來辨別動物的聲音,例如分辨不同青蛙的叫聲,用於生態觀測。聲紋辨識讓「聽聲辨人」變成現實,不再只是小說裡的情節。
★聲音複製 機器能學人說話
另一項引人注目的技術是聲音複製(Voice Cloning),也就是用AI來模仿一個人的說話聲音。想像一下,只要提供一段某人的錄音,電腦就能學會他的聲音特質,然後合成出幾乎以假亂真的講話聲音──這聽起來像不像科幻情節?現在的技術正朝這方向邁進。
聲音複製的基本做法,是收集目標說話者的音頻樣本,透過機器學習訓練一個模型,讓AI掌握該說話者獨特的聲紋特徵。每個人的聲音在音高、語調、口音上都有些獨特之處,AI會「學習」這些細節,進而能夠創造出跟原聲極為相似的新語音。目前一些人工智慧服務已經可以在錄入幾十秒到幾分鐘的聲音後,就複製出那個人聲音的數位模型。
聲音複製有許多正當且有趣的應用場景:例如名人配音,如果某電影角色的原演員無法到場錄音,就可以用AI複製聲音來配製新對白,讓觀眾幾乎聽不出區別。又或者製作有聲書時,能夠讓已故作家的聲音「復活」,親自「朗讀」自己的作品,帶給聽眾特別的體驗。對於失去聲音能力的病患,聲音複製技術甚至有望讓他們透過電腦發出與本人相近的聲音,大大提升溝通的自信和生活品質。
當然,聲音複製也引發一些倫理和安全問題,例如有人擔心不法之徒用它來冒充他人聲音進行詐騙。因此,科技界也研究如何加入水印或識別技術,防止聲音被不當濫用。但總括來說,聲音複製展示了AI的驚人潛力:機器不僅能聽會辨,還能開口「說話」。未來我們或許會和「語音分身」互動,體驗許多新奇的應用。
●作者為教育部高中數學學科中心研究教師、台北市3A教學基地中心主任,獲北市特殊優良教師。


